Pipeline steps are executed sequentially by default. You can optionally use the depends_on keywork to describe your build steps as a directed acyclic graph. In the below example, steps foo and bar execute in parallel, and baz executes once both steps complete.
kind: pipeline
name: foo
steps:
- name: foo
image: golang
commands:
- go build
- go test
- name: bar
image: node
commands:
- npm install
- npm test
- name: baz
image: plugins/slack
settings:
webhook:
from_secret: webhook
depends_on:
- foo
- bar
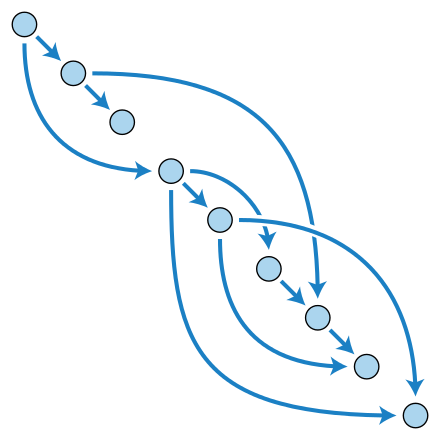
The above example is quite simple, but you could use this syntax to create very complex execution flows. The below diagram provides a visual representation of what a complex graph execution could look like:
It seems like depends_on on 3rd task implicitly declares tasks 1 and 2 to be executed in parallel. Am I right? This implicitness is very confusing IMO.
if I want let all step run at the same time , I have to create a useless step with a depends_on include a step name. it don’t seem good , any others better resolve way ?
AFAICT, and related to @907 concerns, as soon as you use depends_on in one place, everything that is declared later in the file without a depends_on runs in parallel. This means that you have to construct a DAG for all the steps that follow the first use of depends_on, even if you just want a few steps in the middle to run in parallel.
As it stands right now, to linearize the steps following some parallel piece, each step has to link to the previous step by name – definitely an anti-pattern smearing of concerns…
The generality of depends_on certainly has more power than group, but it is in no way a simple replacement for group.
At the risk of introducing unintended semantics, I could imagine that a depends_on_previous: null declaration could be used to turn off the parallelism for subsequent steps…
I’ve now struggled to restore the parallel behavior we used to enjoy with group – PITA. E.g. the semantics of depends_on are not clear, e.g. when it refers to a build step that isn’t being run due to when… A step should not have to worry about other steps.
The more I think about this, the more I think that the most reasonable way to allow parallelism within a build would be to declare the DAG separately, giving each node in the DAG a name. A node would be a placeholder for steps to run in parallel. Each step would have to declare which node it belongs to. All steps in a node would run in parallel (so a node is like a named group), and the DAG of nodes would determine the constraints among the nodes of parallel steps. Empty nodes (due to when) would be epsilons.
There is prior art for our design decisions, inspired by the google cloud builder syntax. I understand some people dislike depends_on while others are happily using it. The point is moot since we are not making any breaking changes to the yaml now that 1.0 is released.
On second thought, depending on the previous step is sometimes wasteful on the overall run time. Forcing me to declare the actual dependency is fine, I guess.
I’ve come around to enjoying what depends_on: enables, and I have implemented a complex DAG for our build/test/deploy/test setup.
I do have one request that relates to my initial (and continuing) difficulties. The problem occurs if a when: eliminates a job from the DAG. The missing job breaks the chain of dependencies, and downstream jobs start too soon (as if they have an epsilon to the start node).
Request:
Could you please expand a node’s dependencies to the transitive closure of its parents beforewhen: is used to eliminate arcs from the DAG. I believe this will result in far few surprises and lets dependencies be “local”, focussing on immediate predecessors. I am hard-pressed to think of working examples that will be broken by this change (but I’m sure a pathological one can be dreamed up) – anyone who’s run into this problem will have coded the transitive closure by hand already, as I have done.
I cannot reproduce. Maybe you are running an older version? I have the below pipeline where the second step is skipped (does not match branch) and the third step depends on the second step:
If you look at the underlying implementation you will notice that Drone visits every single node in the graph. It does not alter the graph or break the chain in any way. Here is some pseudo code to illustrate.
run := func(s *Step) error {
if s.When(...) == true { // step bar will not match
return s.Exec()
}
return nil
}
var d dag.Runner
d.AddVertex("foo", run)
d.AddVertex("bar", run) // added to graph despite being skipped
d.AddVertex("baz", run)
d.AddEdge("bar", "foo")
d.AddEdge("baz", "bar")
d.Run()
I recommend providing a simplified example to reproduce the problem because I cannot reproduce and my time is scarce. If you can provide a simple way to reproduce I would be happy to dig deeper.
I would also like the option to limit parallelism.
Right now I am building a mono-repo, that has 8 parallel build steps. However, as the drone worker handles 4 pipelines at once, using more than 2 processes means that the other workers on the same machine suffer from cpu starvation, sometimes leading to test timeouts.
Having a ‘maxParallelism: 2’ option would help here, to limit the pipeline to execute at most 2 steps at once.